[XBONE/SCORPIO] Topic Oficial
Publicado: 04/02/13 12:13
La sucesora de XBOX360 ya esta en camino, cada dia se filtran mas cosas, aunque sin confirmacion oficial no podemos asegurar que la version definitiva sea asi
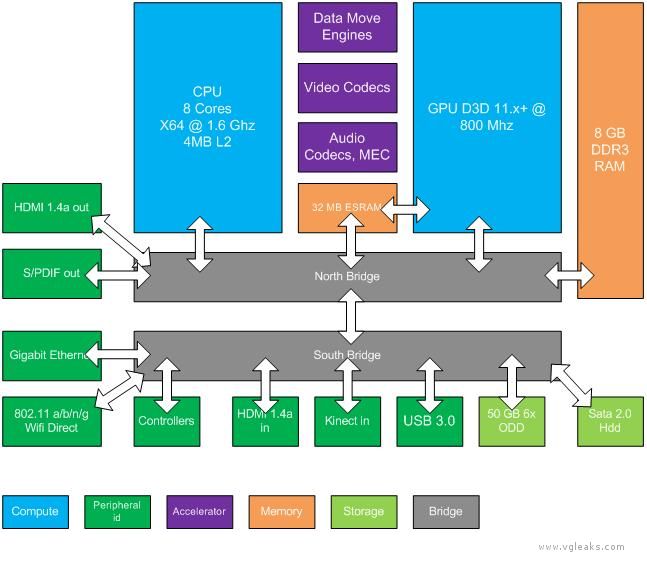
CPU:
- x64 Architecture
- 8 CPU cores running at 1.6 gigahertz (GHz)
- each CPU thread has its own 32 KB L1 instruction cache and 32 KB L1 data cache
- each module of four CPU cores has a 2 MB L2 cache resulting in a total of 4 MB of L2 cache
- each core has one fully independent hardware thread with no shared execution resources
- each hardware thread can issue two instructions per clock
GPU:
- custom D3D11.1 class 800-MHz graphics processor
- 12 shader cores providing a total of 768 threads
- each thread can perform one scalar multiplication and addition operation (MADD) per clock cycle
- at peak performance, the GPU can effectively issue 1.2 trillion floating-point operations per second
High-fidelity Natural User Interface (NUI) sensor is always present
Almacenamiento y memoria:
- 8 gigabyte (GB) of RAM DDR3 (68 GB/s)
- 32 MB o embedded SRAM (ESRAM) (102 GB/s)
- from the GPU’s perspective the bandwidths of system memory and ESRAM are parallel providing combined peak bandwidth of 170 GB/sec.
- Disco Rigido en todas las versiones
- 50 GB 6x Blu-ray Disc drive
Conexiones:
- Gigabit Ethernet
- Wi-Fi y Wi-Fi Direct
Hardware Accelerators:
- Move engines
- Image, video, and audio codecs
- Kinect multichanel echo cancellation (MEC) hardware
- Cryptography engines for encryption and decryption, and hashing

Virtual Addressing
All GPU memory accesses on Durango use virtual addresses, and therefore pass through a translation table before being resolved to physical addresses. This layer of indirection solves the problem of resource memory fragmentation in hardware—a single resource can now occupy several noncontiguous pages of physical memory without penalty.
Virtual addresses can target pages in main RAM or ESRAM, or can be unmapped. Shader reads and writes to unmapped pages return well-defined results, including optional error codes, rather than crashing the GPU. This facility is important for support of tiled resources, which are only partially resident in physical memory
ESRAM
Durango has no video memory (VRAM) in the traditional sense, but the GPU does contain 32 MB of fast embedded SRAM (ESRAM). ESRAM on Durango is free from many of the restrictions that affect EDRAM on Xbox 360. Durango supports the following scenarios:
•Texturing from ESRAM
•Rendering to surfaces in main RAM
•Read back from render targets without performing a resolve (in certain cases)
The difference in throughput between ESRAM and main RAM is moderate: 102.4 GB/sec versus 68 GB/sec. The advantages of ESRAM are lower latency and lack of contention from other memory clients—for instance the CPU, I/O, and display output. Low latency is particularly important for sustaining peak performance of the color blocks (CBs) and depth blocks (DBs).
Local Shared Memory and Global Shared Memory
Each shader core of the Durango GPU contains a 64-KB buffer of local shared memory (LSM). The LSM supplies scratch space for compute shader threadgroups. The LSM is also used implicitly for various purposes. The shader compiler can choose to allocate temporary arrays there, spill data from registers, or cache data that arrives from external memory. The LSM facilitates passing data from one pipeline stage to another (interpolants, patch control points, tessellation factors, stream out, etc.). In some cases, this usage implies that successive pipeline stages are restricted to run on the same SC.
The GPU also contains a single 64-KB buffer of global shared memory (GSM). The GSM contains temporary data referenced by an entire draw call. It is also used implicitly to enforce synchronization barriers, and to properly order accesses to Direct3D 11 append and consume buffers. The GSM is capable of acting as a destination for shader export, so the driver can choose to locate small render targets there for efficiency.
Cache
Durango has a two stage caching system, depicted below.
L2 Cache
The GPU contains four separate 8-way L2 caches of 128 KB, each composed of 2048 64-byte cache lines. Each L2 cache owns a certain subset of address space. Texture tiling patterns are chosen to ensure all four caches are equally utilized. The L2 generally acts as a write-back cache—when the GPU modifies data in a cache line, the modifications are not written back to main memory until the cache line is evicted. The L2 cache mediates virtually all memory access across the entire chip, and supplies a variety of types of data, including shader code, constants, textures, vertices, etc., coming either from main RAM or from ESRAM. Shader atomic operations are implemented in the L2 cache.
L1 Cache
Each shader core has a local 64-way L1 cache of 16 KB, composed of 256 64-byte cache lines. The L1 generally acts as a write-through cache—when the SC modifies data in the cache, the modifications are pushed back to L2 without waiting until the cache line is evicted. The L1 cache is used exclusively for data read and written by shaders and is dedicated to coalescing memory requests over the lifetime of a single vector. Even this limited sort of caching is important, since memory accesses tend to be very spatially coherent, both within one thread and across neighboring threads.
The L1 cache guarantees consistent ordering per thread: A write followed by a read from the same address, for example, will give the updated value. The L1 cache does not, however, ensure consistency across threads or across vectors. Such requirements must be enforced explicitly—using barriers in the shader for example. Data is not shared between L1 caches or between SCs except via write-back to the L2 cache.
Unlike some earlier GPUs (including the Xbox 360 GPU), Durango leaves texture and buffer data in native compressed form in the L2 and L1 caches. Compressed data implies a longer fetch pipeline—every L1 cache must now have decoder hardware in it that repeats the same calculation each time the same data is fetched. On the other hand, by keeping data compressed longer, the GPU limits cache footprint and intermediate bandwidth. Following the same principle, sRGB textures are left in gamma space in the cache, and, therefore, have the same footprint as linear textures.
To see how this policy affects cache efficiency, consider an sRGB BC1 texture—perhaps the most commonly encountered texture type in games. BC1 is a 4-bit per texel format; on Durango, this texture occupies 4 bits per texel in the L1 cache. On Xbox 360, the same texture is decompressed and gamma corrected before it reaches the cache, and therefore occupies 8 bytes per texel, or 16 times the Durango footprint. For this reason, the Durango L1 cache behaves like a much larger cache when compared against previous architectures.
Just as SCs can hide fetch latency by switching to other vectors, L1 texture caches on Durango are capable of hiding L2 cache latency by continuing to process fetch instructions after a miss. In other words, when a cache miss is followed by one or more cache hits, the hits can be satisfied during the stall for the miss.
Fetch
Durango supports two types of fetch operation—image fetches and buffer fetches. Image fetches correspond to the Sample method in high-level shader language (HLSL) and require both a texture register and a sampler register. Features such as filtering, wrapping, mipmapping, gamma correction, and block compression require image fetches. Buffer fetches correspond to the Load method in HLSL and require only a texture register, without a sampler register. Examples of buffer fetches are:
•Vertex fetches
•Direct3D 10-style gather4 operations (which fetch a single unfiltered channel from 4 texels, rather than multiple filtered channels from a single texel)
•Fetches from formats that are natively unfilterable, such as integer formats
Image fetches and buffer fetches have different performance characteristics. Image fetches are generally bound by the speed of the texture pipeline and operate at a peak rate of four texels per clock. Buffer fetches are generally bound by the write bandwidth into the destination registers and operate at a peak rate of 16 GPRs per clock. In the typical case of an 8-bit four-channel texture, these two rates are identical. In other cases, such as a 32-bit one-channel texture, buffer fetch can be up to four times faster.
Many factors can reduce effective fetch rate. For instance, trilinear filtering, anisotropic filtering, and fetches from volume maps all translate internally to iterations over multiple bilinear fetches. Bilinear filtering of data formats wider than 32-bits per texel also operates at a reduced rate. Floating point formats that have more than three channels operate at half rate. Use of per-pixel gradients causes fetches to operate at quarter rate.
By contrast, fetches from sRGB textures are full rate. Gamma conversion internally uses a modified 7e4 floating-point representation. This format is large enough to be bitwise exact according to the DirectX 10 spec, yet still small enough to fit through a single filtering pipe.
The Durango GPU supports all standard Direct3D 11 DXGI formats, as well as some custom formats.
Compute
Each of the 12 Durango SCs has its own L1 cache, LSM (Local Shared Memory), and scheduler, and four SIMD units. O represents a single thread of the currently executing shader.
SIMD
Each of the four SIMDs in the shader core is a vector processor in the sense of operating on vectors of threads. A SIMD executes a vector instruction on 64 threads at once in lockstep. Per thread, however, the SIMDs are scalar processors, in the sense of using float operands rather than float4 operands. Because the instruction set is scalar in this sense, shaders no longer waste processing power when they operate on fewer than four components at a time. Analysis of Xbox 360 shaders suggests that of the five available lanes (a float4 operation, co-issued with a float operation), only three are used on average.
The SIMD instruction set is extensive, and supports 32-bit and 64-bit integer and float data types. Operations on wider data types occupy multiple processor pipes, and therefore run at slower rates—for example, 64-bit adds are one-eighth rate, and 64-bit multiplies are 1/16-rate. Transcendental operations, such as square root, reciprocal, exponential, logarithm, sine, and cosine, are non-pipelined and run at quarter rate. These operations should be used sparingly on Durango because they are more expensive relative to arithmetic operations than they are on Xbox 360.
Scheduler
The scheduler of the SC is responsible for loading shader code from memory and controlling execution of the four SIMDs. In addition to managing the SIMDs, the scheduler also executes certain types of instructions on its own. These instructions come from a separate scalar instruction set; they perform an operation per vector rather an operation than per thread. A scalar instruction might be employed, for example, to add two shader constants. In microcode, scalar instructions have names beginning with s_, while vector instructions have names beginning with v_.
The scheduler tracks dependencies within a vector, keeping track of when the next instruction is safe to run. In addition, the scheduler handles dynamic branch logic and loops.
On each clock cycle, the scheduler considers one of the four SIMDs, iterating over them in a round-robin fashion. Most instructions have a four cycle throughput, so each SIMD only needs attention once every four clocks. A SIMD can have up to 10 vectors in flight at any time. The scheduler selects one or more of these 10 candidate vectors to execute an instruction. The scheduler can simultaneously issue multiple instructions of different types—for instance, a vector operation, a scalar operation, a global memory operation, a local memory operation, and a branch operation—but each operation must act on a different vector.
General Purpose Registers
Each SIMD contains 256 vector general purpose registers (VGPRs), and 512 scalar general purpose registers (SGPRs). Both types of GPR store 32-bit data: An SGPR contains a single 32-bit value shared across threads, while a VGPR represents an array of 32-bit values, one per thread within a vector. Each thread can only see its own entry within a VGPR.
GPRs record intermediate results between instructions of the shader. To each newly created vector, the GPU assigns a range of VGPRs and a range of SGPRs—as many as needed by the shader up to a limit of 256 VGPRs and 104 SGPRs. Some GPRs are consumed implicitly by the system—for instance, to hold literal constants, index inputs, barycentric coordinates, or metadata for debugging.
The number of available GPRs can be a limiting factor in the ability of the SIMD to hide latency by switching to other vectors. If all the GPRs for a SIMD are already assigned, then no new vector can begin executing. And then, if all active vectors stall, the SIMD goes idle until one of the stalls ends.
Like most modern GPUs, the Durango GPU uses a unified shader architecture (USA), which means that the same SCs are used interchangeably for all stages of the shader pipeline: vertex, hull, domain, geometry, pixel, and compute. On Durango, GPR usage is also unified; there is no longer any fixed allocation of GPRs to vertex or pixel shading as on Xbox 360.
Constants
The Durango GPU has no dedicated registers to hold shader constants. When a shader references a constant buffer, the compiler decides how these accesses will be implemented. The compiler can specify that constants be preloaded into GPRs. The compiler may fetch constants from memory by using scalar instructions. The compiler may cache constants in the LSM.
A shader constant may be either global (constant over the whole draw call) or indexed (immutable, but varying by thread). Indexed constants must be fetched using vector instructions, and are correspondingly more expensive than global constants. This cost is somewhat analogous to the constant waterfalling penalty from Xbox 360, although the mechanism is different.
Branches
Branch instructions are executed by the scheduler and have the same ideal cost as computation instructions. Just as they do on CPUs, however, branches may incur pipeline stalls while awaiting the result of the instruction which determines the branch direction. Not-taken branches introduce subsequent pipeline bubbles. Taken branches require a read from the instruction cache, which incurs an additional delay. All these potential costs are moot as long as there are enough active vectors to hide the stalls.
Branching is inherently problematic on a SIMD architecture where many threads execute in lockstep, and agreement about the branch direction is not guaranteed. The HLSL compiler can implement branch logic in one of several ways:
•Predication – Both paths are executed; calculations that should not happen for a particular thread are masked out.
•Predicated jump – If all threads decide the branch in the same way, only the correct path is executed; otherwise, both paths are executed.
•Skip – Both paths are followed, but instructions that are executed by no threads are skipped over at a faster rate.
Interpolation
The Durango GPU has no fixed function interpolation units. Instead, a dedicated GPU component routes vertex shader output data to the LSM of whichever SC (or SCs) ends up running the pixel shader. This routing mechanism allows pixels to be shaded by a different SC than the one that shaded the associated vertices.
Before pixel shader startup, the GPU automatically populates two registers with interpolation metadata:
•One SGPR is a bitfield that contains: •a pointer to the area of the LSM where vertex shader output was stored
•a description of which pixels in the current vector came from which vertices
•Two VGPRs contain barycentric coordinates for each pixel (the third barycentric coordinate is implicit)
It is the responsibility of the shader compiler to generate microcode prologues that perform the actual interpolation calculations. The SCs have special purpose multiply-add instructions that read some of their inputs directly from the LSM. A single float interpolation across a triangle can be accomplished by using two of these instructions.
This approach to interpolation has the advantage that there is no cost for unused interpolants—the instructions can be omitted or branched over. Conversely, there is no benefit from packing interpolants into float4’s. Nevertheless, for short shaders, interpolation can still significantly impact overall computation load.
Output
Pixel shading output goes through the DB and CB before being written to the depth/stencil and color render targets. Logically, these buffers represent screenspace arrays, with one value per sample. Physically, implementation of these buffers is much more complex, and involves a number of optimizations in hardware.
Both depth and color are stored in compressed formats. The purpose of compression is to save bandwidth, not memory, and, in fact, compressed render targets actually require slightly more memory than their uncompressed analogues. Compressed render targets provide for certain types of fast-path rendering. A clear operation, for example, is much faster in the presence of compression, because the GPU does not need to explicitly write the clear value to every sample. Similarly, for relatively large triangles, MSAA rendering to a compressed color buffer can run at nearly the same rate as non-MSAA rendering.
For performance reasons, it is important to keep depth and color data compressed as much as possible. Some examples of operations which can destroy compression are:
•Rendering highly tessellated geometry
•Heavy use of alpha-to-mask (sometimes called alpha-to-coverage)
•Writing to depth or stencil from a pixel shader
•Running the pixel shader per-sample (using the SV_SampleIndex semantic)
•Sourcing the depth or color buffer as a texture in-place and then resuming use as a render target
Both the DB and the CB have substantial caches on die, and all depth and color operations are performed locally in the caches. Access to these caches is faster than access to ESRAM. For this reason, the peak GPU pixel rate can be larger than what raw memory throughput would indicate. The caches are not large enough, however, to fit entire render targets. Therefore, rendering that is localized to a particular area of the screen is more efficient than scattered rendering.
Fill
The GPU contains four physical instances of both the CB and the DB. Each is capable of handling one quad per clock cycle for a total throughput of 16 pixels per clock cycle, or 12.8 Gpixel/sec. The CB is optimized for 64-bit-per-pixel types, so there is no local performance advantage in using smaller color formats, although there may still be a substantial bandwidth savings.
Because alpha-blending requires both a read and a write, it potentially consumes twice the bandwidth of opaque rendering, and for some color formats, it also runs at half rate computationally. Likewise, because depth testing involves a read from the depth buffer, and depth update involves a write to the depth buffer, enabling either state can reduce overall performance.
Depth and Stencil
The depth block occurs near the end of the logical rendering pipeline, after the pixel shader. In the GPU implementation, however, the DB and the CB can interact with rendering both before and after pixel shading, and the pipeline supports several types of optimized early decision pathways. Durango implements both hierarchical Z (Hi-Z) and early Z (and the same for stencil). Using careful driver and hardware logic, certain depth and color operations can be moved before the pixel shader, and in some cases, part or all of the cost of shading and rasterization can be avoided.
Depth and stencil are stored and handled separately by the hardware, even though syntactically they are treated as a unit. A read of depth/stencil is really two distinct operations, as is a write to depth/stencil. The driver implements the mixed format DXGI_FORMAT_D24_UNORM_S8_UINT by using two separate allocations: a 32-bit depth surface (with 8 bits of padding per sample) and an 8-bit stencil surface.
Antialiasing
The Durango GPU supports 2x, 4x, and 8x MSAA levels. It also implements a modified type of MSAA known as compressed AA. Compressed AA decouples two notions of sample:
•Coverage sample–One of several screenspace positions generated by rasterization of one pixel
•Surface sample– One of several entries representing a single pixel in a color or depth/stencil surface
Traditionally, coverage samples and surface samples match up one to one. In standard 4xMSAA, for example, a triangle may cover from zero to four samples of any given pixel, and a depth and a color are recorded for each covered sample.
Under compressed AA, there can be more coverage samples than surface samples. In other words, a triangle may still cover several screenspace locations per pixel, but the GPU does not allocate enough render target space to store a unique depth and color for each location. Hardware logic determines how to combine data from multiple coverage samples. In areas of the screen with extensive subpixel detail, this data reduction process is lossy, but the errors are generally unobjectionable. Compressed AA combines most of the quality benefits of high MSAA levels with the relaxed space requirements of lower MSAA levels.
Resumen en tablita

Fuente:VGleaks
Vgleaks
Perdon que este todo en ingles, es que es demaciado y ademas hay muchos datos "tecnicos"